Pourquoi cet écosystème
J'avais besoin d'une plateforme opérée comme une PME, mais à l'échelle d'une personne. Reproductible, observable, documentée — et qui me serve aussi de surface d'apprentissage sur ce qu'une équipe complète aurait construit autrement.
TOGAF — le cadre
Je travaille avec le framework TOGAF et ses quatre domaines d'architecture (BDAT) :
-
Architecture métier (Business) — quels services rendus, à qui : à moi (knowledge, hub-projects, ledger, memories), à mes lecteurs (hub-www), à mes agents IA (mcp-unified).
-
Architecture applicative (Application) — la décomposition logique en applications, leurs interfaces, leurs interactions : chaque brique est un microservice autonome qui expose une API HTTP/JSON pour les humains, des tool calls MCP pour les agents IA, et écoute/émet des événements via postgres LISTEN/NOTIFY pour le bus interne.
-
Architecture des données (Data) — où vivent les états, quelles entités, quels flux : postgres pgvector pour la knowledge sémantique, postgres dédiés ou partagés pour les états métier, Ghost pour le CMS, fichiers Markdown versionnés pour les drafts éditoriaux.
-
Architecture technique (Technology) — l'infrastructure qui fait tourner tout ça : cluster Kubernetes k3s self-host (trois nodes), charts Helm OCI packagés à chaque commit, GitOps via hub-deploy, registre harbor self-host, runtime NVIDIA pour les charges GPU (hub-ollama, hub-whisperx).
Chaque article du blog raconte une décision dans l'un de ces quatre domaines. Le pattern MCP-first est l'invariant qui les relie tous.
DDD — la décomposition
Chaque brique est traitée comme un bounded context au sens du Domain Driven Design, dans une vraie architecture microservices : chaque projet est codé en autonomie, dans son repo, son chart, son cycle de vie, et se branche à la plateforme via un protocole commun. C'est l'angle structurel qui rend l'ensemble tenable à mon échelle — chaque brique peut évoluer ou casser sans entraîner ses voisines.
Trois disciplines maintenues volontairement.
-
Un ubiquitous language aussi unifié que possible, mais pas dogmatique. Je suis fort partisan d'un vocabulaire commun à toute la plateforme — écrit dans la knowledge, lu par mes agents IA avant qu'ils ne génèrent. En pratique, un même terme prend parfois deux sens dans deux métiers différents, et c'est très bien comme ça : nous, humains, on comprend l'implicite par le contexte. La langue, c'est aussi ça. On documente seulement les cas où l'ambiguïté coûterait cher.
-
Une anti-corruption layer entre chaque microservice. Les briques ne se parlent jamais par appel direct : elles passent par des proxys (hub-dashboard pour l'humain, mcp-unified pour l'IA, postgres pour les états partagés). C'est ce qui rend l'autonomie réelle : un service peut changer son schéma interne sans casser ses voisins, la couche d'adaptation absorbe.
-
Pas de partage de modèles, mais un protocole de communication unifié. Chaque microservice est autonome — ses entités, ses migrations, sa BD si nécessaire. Mais la manière dont il parle aux autres (HTTP/JSON pour les API publiques, événements postgres LISTEN/NOTIFY pour le bus interne, MCP tool calls pour les agents IA) suit des conventions communes à l'écosystème. L'autonomie en bas, l'uniformité en haut.
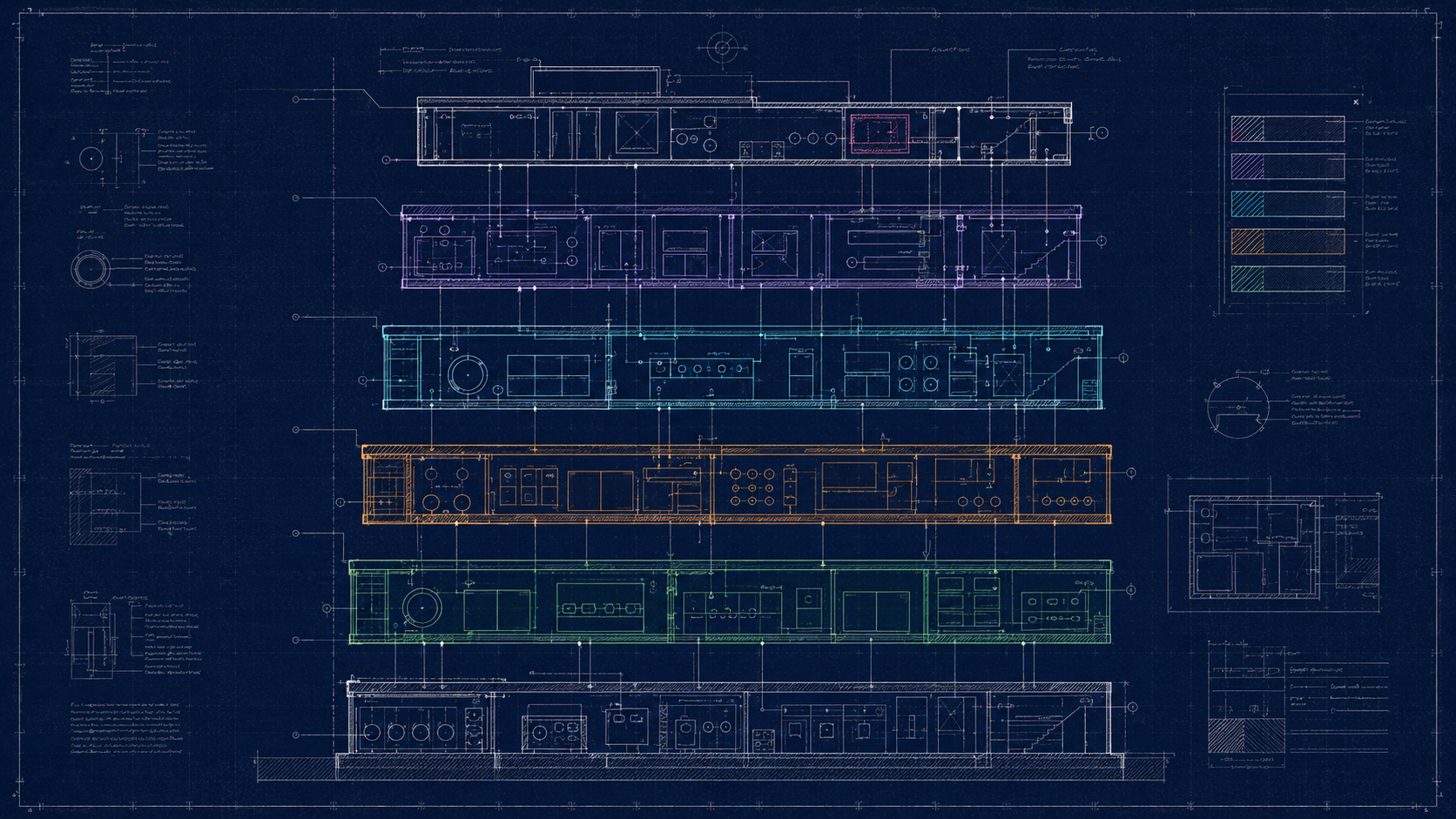
Conventions hub-* — la mise en œuvre
Tous les composants ci-dessus suivent la même structure opérationnelle :
- 1 projet = 1 repo GitHub privé, nommé
hub-<chose>(sauf produits). - 1 chart Helm OCI embarqué dans le repo (
helm/), packagé à chaque commit, publié dans harbor. - 1 fichier
VERSIONsemver, auto-bumpé par la CI à chaque push surmain. C'est l'invariant qui rend l'opération sereine : je ne touche jamais ce fichier à la main. Je code (souvent à deux avec Claude), je commit, je push. La CI bumpe le patch, build l'image, push l'image et le chart OCI vers harbor avec le bon tag, et tag le commit. Quand elle a fini, la nouvelle version existe pour de vrai dans harbor. - 1 entrée dans
versions.yamlcôté hub-deploy (le GitOps). Une fois la nouvelle version visible dans mon dashboard, je modifie uniquement le numéro sur la ligne du service concerné, je push. Le CD se charge du reste :helm upgrade --installavec la nouvelle version OCI. - 1
.github/copilot-instructions.mdqui pointe vers la knowledge centrale via MCP. L'agent IA lit ces invariants avant chaque session.
Le bump CI est ce qui élimine la classe d'erreur la plus pénible — « on a déployé une version qui n'existe pas » — parce qu'à l'instant où la CI termine, l'image et le chart sont disponibles dans harbor sous le nouveau tag, et le numéro est synchronisé partout (VERSION, tag Docker, chart Helm). Quand versions.yaml pointe vers ce numéro, il pointe vers quelque chose qui tourne.
Cette répétition n'est pas un dogme — c'est ce qui rend tenable d'opérer trente briques en solo. Quand tout parle la même langue, n'importe quel changement local devient un patch propre, pas une opération chirurgicale.
Le détail de la transition Compose → k3s, des charts OCI, des cascades de migrations sont racontés dans les articles du blog. Cette page-ci est volontairement courte : elle montre ce qui tourne et selon quels principes — le pourquoi de chaque décision vit dans le journal.